.png&w=3840&q=75)
米国のAIスタートアップ「Sesame(セサミ)」が、この人間らしい会話の特徴を再現する音声AI技術「Conversational Speech Model(CSM)」を発表し、大きな注目を集めています。このモデルは、従来の機械的な音声アシスタントとは一線を画し、感情表現や自然な会話の流れを実現したことで、SNS上で「映画『her/世界でひとつの彼女』が現実になった」と話題になっています。

なぜ「声のプレゼンス」が重要なのか
Sesameの共同創業者であるブレンダン・アイリブ氏とアンキット・クマール氏らは、現在の音声アシスタントの最大の弱点として「感情的な平坦さ(emotional flatness)」を指摘しています。
「感情のない単調な声でしか話せないアシスタントには、初期の新鮮さが過ぎると日常生活に定着することが難しく、長期的には使い手を疲れさせてしまいます」と同社は説明しています。
これに対してSesameが提唱するのが「声のプレゼンス(voice presence)」という概念です。これは会話が「リアルで、理解され、価値あるものと感じられる魔法のような特質」と定義されています。単に命令に応じるだけでなく、本物の対話を通じて信頼関係を築けるAIパートナーを目指しているのです。
CSMの4つの核心技術
Sesameが開発したCSMは、「声のプレゼンス」を実現するために、以下の4つの核心技術に取り組んでいます:
- 感情インテリジェンス: 感情的な文脈を読み取り、適切に応答する能力
- 会話のダイナミクス: 自然なタイミング、間、相槌、言葉の強調など
- 文脈認識: 状況に合わせてトーンやスタイルを調整する能力
- 一貫した個性: 首尾一貫した信頼できる人格の維持
公開されているデモでは、「マヤ」と「マイルズ」という2つのAIキャラクターと会話することができます。特に注目すべきは、「えーと」「そうですね」といった言葉遣いや、呼吸音、考え込むような間の取り方など、人間が無意識にしている会話の特徴を自然に再現している点です。
技術的な仕組み:従来のTTSを超える
CSMの技術的革新は、従来のテキスト読み上げ(TTS)モデルの限界を克服した点にあります。一般的なTTSはテキストから直接音声を生成しますが、自然な会話に必要な文脈の理解が欠けていました。
同社の技術ブログによると、最新のモデルでも「一対多問題」に苦戦しているといいます。一つの文章を話す方法は無数にありますが、特定の状況に適した話し方はごく一部です。トーン、リズム、会話の履歴といった追加の文脈がなければ、モデルは最適な選択をするための情報が不足してしまうのです。
CSMはこの問題に対し、トランスフォーマーを使用したエンド・ツー・エンドのマルチモーダル学習として問題を捉え直しました。会話の履歴を活用することで、より自然で一貫性のある音声を生成します。
技術的には、CSMは2つの自己回帰型トランスフォーマーを使用しています:
- マルチモーダルバックボーン:テキストと音声を交互に処理し、最初のコードブックレベルをモデル化
- 音声デコーダー:残りのコードブックを処理して高忠実度の音声を再構築
特に重要なのは、CSMが「シングルステージモデル」として機能する点です。これにより処理効率と表現力が向上し、リアルタイム会話でもより自然な応答が可能になっています。
前例のない評価方法
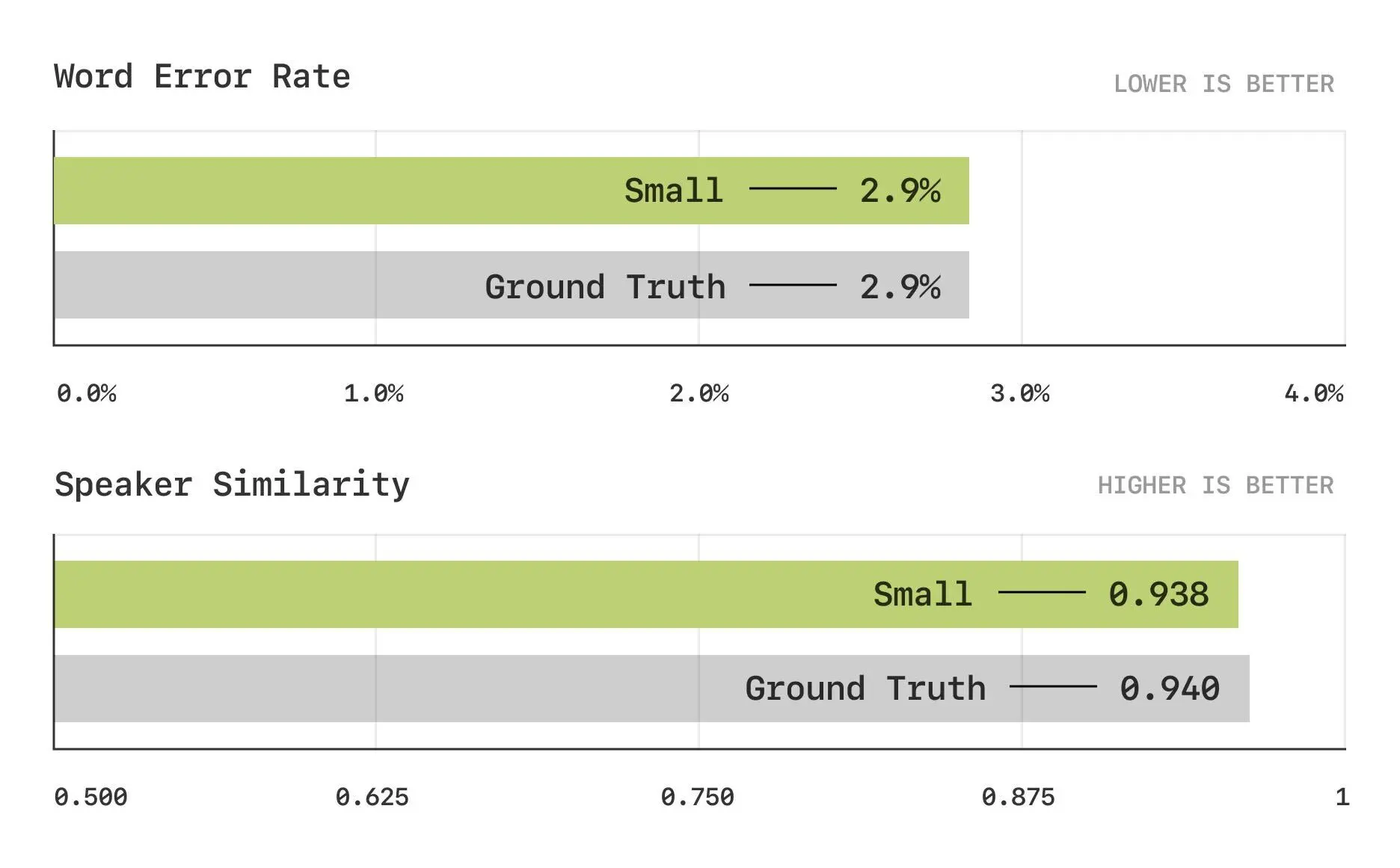
Sesameは、従来の評価方法では測定できない会話能力を評価するための新しい評価スイートも開発しました。従来の指標である単語誤り率(WER)やスピーカー類似性(SIM)では、最新モデルはすでに人間に近いパフォーマンスに達しているため、新たな基準が必要だったのです。
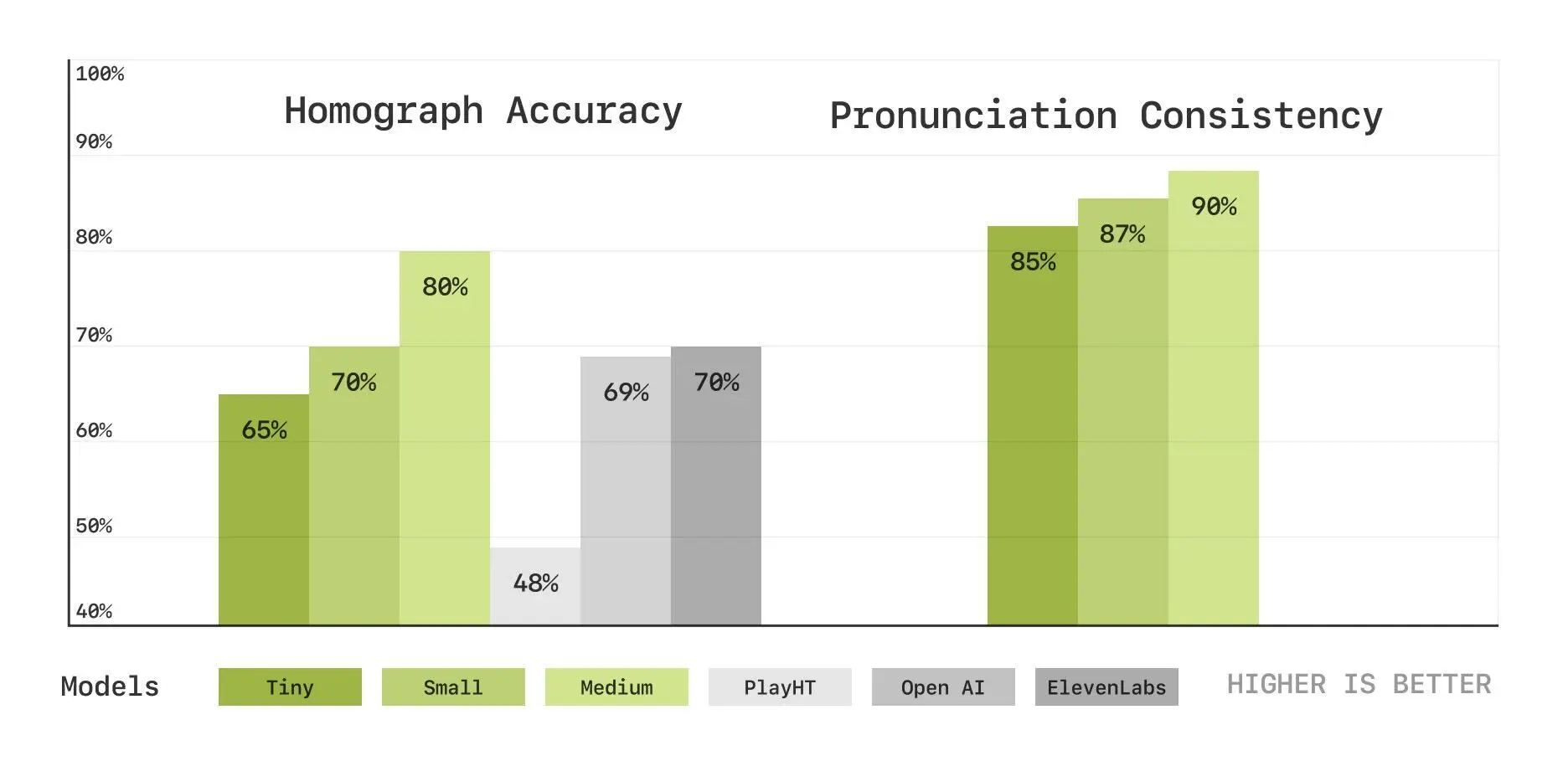
新しい評価指標には以下のようなものがあります:
- 同形異義語の区別:同じ綴りで異なる発音を持つ単語(例:英語の"lead"が金属の「鉛」か「導く」かなど)を正しく発音できるかを評価
- 発音の継続一貫性:複数の発音バリエーションがある単語(例:"route"を/raʊt/と発音するか/ruːt/と発音するか)を会話の中で一貫して使えるかを評価
主観評価では興味深い結果が出ています。文脈なしの場合、人間の評価者はCSMの音声と人間の音声を区別できないレベルに達していますが、会話の文脈が加わると、まだ人間の自然さには及ばないことが明らかになりました。
これは、単一の発話としての自然さはすでに実現できているものの、会話全体の流れの中での適切な表現にはまだ改善の余地があることを示しています。
SNSでの反響
このデモ版は、リリース後すぐにSNS上で大きな反響を呼びました。ECプラットフォーム大手Shopifyの CEO トビ・ルトケ氏は「Sesameの音声モデルは信じられないほど素晴らしい。絶対に試すべき」とコメント。Vercelの CEO ギレルモ・ラウチ氏も「驚くべき音声AIデモ。サイト体験全体が素晴らしい」と絶賛しています。
多くのユーザーが、ホアキン・フェニックス主演の2013年映画「her/世界でひとつの彼女」を例に挙げ、AIとの自然な感情的つながりが描かれた映画の世界が現実になりつつあると指摘しています。
大規模データセットとモデルスケーリング
Sesameの技術は膨大なデータセットに支えられています。公式ブログによると、公開されている音声データを書き起こし、話者分離、セグメント化した後、約100万時間の主に英語の音声データを使用してモデルを訓練しています。
同社は3種類のモデルサイズを訓練しました:
- Tiny:10億パラメータのバックボーン、1億パラメータのデコーダー
- Small:30億パラメータのバックボーン、2.5億パラメータのデコーダー
- Medium:80億パラメータのバックボーン、3億パラメータのデコーダー
評価結果からは、モデルサイズが大きくなるほどパフォーマンスが向上することが示されており、より大きなモデルでさらにリアルな音声合成が可能になると考えられています。
拡大するAI音声市場での競争
AI音声市場では、Eleven Labs(イレブンラブス)が高品質なテキスト読み上げ機能で注目を集め、企業価値は約6000億円に達しています。OpenAIやGrokなども独自の音声AI開発を進めており、競争は激化しています。
Sesameは創業者のブレンダン・アイリブ氏、アンキット・クマール氏、ライアン・ブラウン氏らによって設立され、サンフランシスコ、ニューヨーク、ベルビューに拠点を持ちます。すでに著名VCのアンドリーセン・ホロウィッツからシリーズAの資金調達を完了しています。
同VCは「Sesameは、次世代コンピューティングの鍵がARグラスのディスプレイではなく、優れた音声システムにあるという、シンプルだが重要な発想に基づいている」と評価しています。「AIオーディオの感情的な平坦さはこれまで疲れるほど不自然でした。しかし、ARグラスから視覚的なディスプレイを取り除き、代わりに素晴らしい音声中心のAIシステムに集中することで、シームレスで直感的なコンピューティング体験を作り出すことができます」と語っています。
「コンピュータに命を吹き込む」ビジョンと今後の展望
Sesameは「コンピュータに命を吹き込む」という明確なビジョンを掲げています。「私たちは、コンピュータが生き生きとした存在になり、私たちが人間同士でするように見て、聞いて、一緒に働く未来を信じています。自然な人の声は、この未来への鍵です」と同社は説明しています。
現在はCSMを通じて「会話の韻律」を高品質に生成できていますが、同社は「CSMは会話の内容(テキストと音声)のみをモデル化できるが、会話自体の構造はモデル化できていない」と限界も認めています。
人間の会話は、順番交代、間、ペースなど複雑なプロセスを含んでいます。同社は「AIの会話の未来は、データからこれらのダイナミクスを暗黙的に学習できる完全二重(fully duplex)モデルにある」と考えており、データ収集からポストトレーニング方法まで、根本的な変革を進めていくとしています。
今後数ヶ月で、モデルサイズの拡大、データセット量の増加、20言語以上への言語サポート拡大を計画しています。また、事前訓練された言語モデルの活用方法も探求し、音声とテキストの両方に深い知識を持つ大規模マルチモーダルモデルの実現を目指しています。
さらに、同社は研究のオープンソース化にも取り組んでおり、Apache 2.0ライセンスでモデルを公開することを約束しています。「会話AIの進化は協力的な取り組みであるべき」という信念のもと、コミュニティが実験し、改良し、発展させることを奨励しています。
音声インターフェースはAIの最も重要な応用分野の一つとして急速に発展しています。Sesameの取り組みは、「感情の平坦さ」という壁を乗り越え、真に共感できるAIパートナーの実現に一歩近づいたと言えるでしょう。人間とAIの関わり方に新たな可能性をもたらす技術として、今後の発展が期待されます。





.png&w=3840&q=75)




