
OpenAIが公開した「PaperBench」は、AIエージェントが最先端AI研究論文を再現する能力を評価するためのベンチマークです。AIエージェントに論文を読ませ、コードを作成させ、実験を実行して結果を検証するまでの一連のプロセスを測定します。機械学習の国際会議ICML 2024から選ばれた20本の論文を対象に、詳細な評価基準に基づく8,316の課題で評価されました。最も性能の高いClaude 3.5 Sonnetでも平均再現スコアは21.0%にとどまり、AI研究の自動化にはまだ課題が多いことが明らかになりました。
AIが最先端研究を再現できるようになったら?
AIシステムが自ら最先端の研究論文を理解し、実装し、実験を行えるようになれば、科学研究の進歩が大きく加速する可能性があります。特にAI自身がAI研究を進められるようになれば、技術の進化がさらに加速するかもしれません。
しかし、現時点でAIはそのような複雑なタスクをどの程度こなせるのでしょうか? OpenAIが発表した「PaperBench」は、まさにその能力を測定するために開発された新しい評価基準です。

PaperBenchとは?評価方法の詳細
PaperBenchでは、2024年の機械学習国際会議(ICML)で注目を集めた20本の優れた研究論文が評価対象となっています。これらは深層強化学習、AIの堅牢性、確率的手法など12の異なる専門領域をカバーしています。
評価プロセスは以下の3段階で行われます:
- 1.タスク - AIエージェントに論文とその補足情報が提供され、論文の実験結果を再現するよう要求されます
- 2.再現 - AIエージェントが作成したコードが新しい環境で実行され、結果が確認されます
- 3.採点 - 実行結果が評価基準(ルーブリック)に基づいて評価されます
「ルーブリック」とは、詳細な採点基準のことです。例えば「コードがデータを正しく読み込めているか」「実験が正しく実行されているか」「結果が論文と一致しているか」といった細かい項目ごとに評価できる仕組みになっています。各論文に対するこの採点基準は、論文の著者と共同で開発されており、専門家の視点が反映されています。
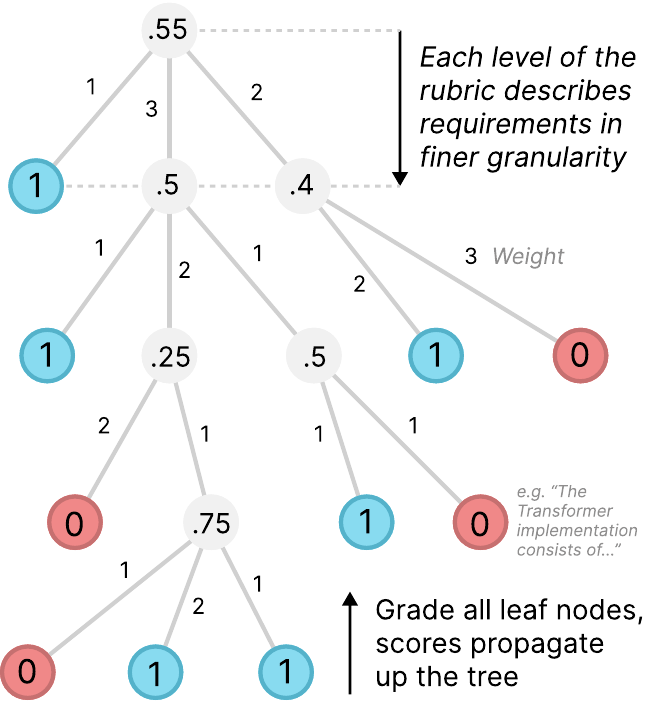
評価項目は大きく3つのタイプに分類されます:
- ・コード開発 - 必要なコードが正しく実装されているか
- ・実行 - 実行スクリプトが正しく動作するか
- ・結果一致 - 実験結果が論文の結果と一致するか
全体で8,316もの個別評価項目があり、AIエージェントの能力を細かく測定できるようになっています。
AIによる自動採点システム
論文の再現評価は本来、専門知識を持つ人間が行う必要があります。しかし、1つの論文の評価に専門家が数十時間を要するため、20本もの論文を繰り返し評価することは現実的ではありません。
そこで研究チームは「SimpleJudge」という大規模言語モデル(LLM)ベースの自動採点システムを開発しました。このシステムは人間の専門家による採点と比較して83%の一致率(F1スコア0.83)を達成し、信頼性の高い代替手段となっています。
この自動採点システムにより、一つの論文の評価コストは約66ドル(約1万円)となり、人間の専門家を雇うよりも大幅に安価で迅速な評価が可能になりました。
各AIモデルの評価結果と分析
PaperBenchでは、現在最先端とされる複数のAIモデルが評価されました:
- ・Claude 3.5 Sonnet: 21.0%(最高性能)
- ・OpenAI o1: 13.2%
- ・DeepSeek-R1: 6.0%
- ・GPT-4o: 4.1%
- ・o3-mini: 2.6%
- ・Gemini 2.0 Flash: 3.2%

最も高い性能を示したClaude 3.5 Sonnetでも平均再現スコアは21.0%にとどまりました。これは注目に値する結果ですが、依然として人間の研究者には及ばない水準です。
研究者たちはAIエージェントのログを詳しく分析し、以下のような問題点を特定しました:
- 1.早期終了
Claude 3.5 Sonnet以外のモデルは、タスクを最後まで続けず、早めに「完了した」と主張したり、「解決できない」と諦めたりする傾向がありました
- 2.計画不足
AIエージェントは限られた時間内で効率よく作業するための計画を立てることができませんでした
- 3.ツール使用の問題
特にo3-miniはコマンド実行などのツールを効果的に使えていませんでした
これらの問題は、AIが複雑で長期的なタスクを実行する能力にまだ大きな課題があることを示しています。AIは計画を立てて説明することはできても、その計画を実際に実行する一連のアクションを取ることが難しいようです。
AIエージェントの改良と効果
研究チームは、AIエージェントのパフォーマンスを向上させるための改良も試みました。基本的なエージェント(BasicAgent)に加えて、タスクを最後まで続けさせ、段階的な作業を促す指示を加えた改良版(IterativeAgent)も開発しました。
この改良により、OpenAI o1のスコアは13.2%から24.4%へと大幅に向上しました。一方で、Claude 3.5 Sonnetのスコアは21.0%から16.1%に低下するという意外な結果も見られました。これは、同じ改良方法でもAIモデルによって効果が異なることを示しています。
また、実行時間を12時間から36時間に延長した場合のo1の性能も評価され、スコアは26.0%まで向上しました。時間をかければ、AIエージェントの性能も向上することが示されています。
人間研究者との比較
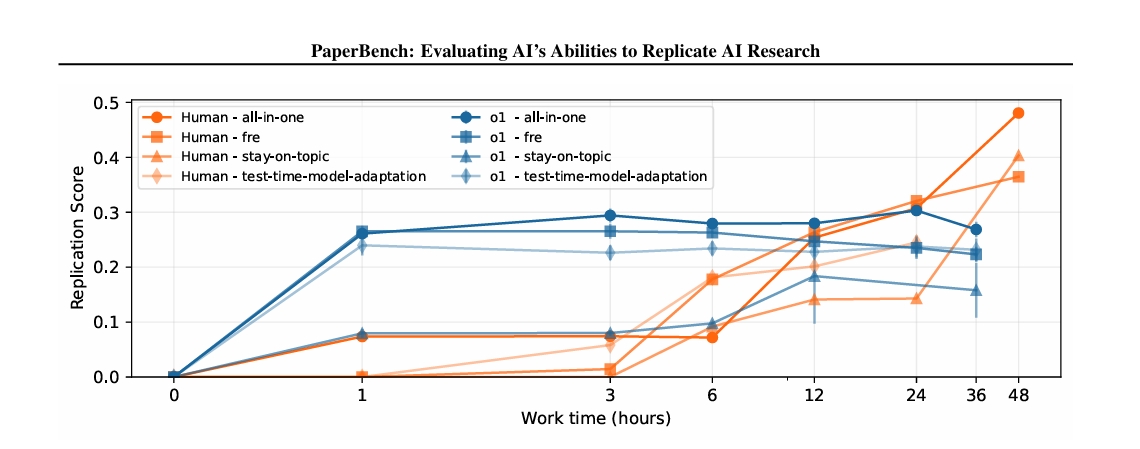
PaperBenchでは、機械学習のPhDを持つ人間研究者8名による再現実験も行われました。4つの論文を対象とした実験では、人間は48時間の作業で平均41.4%のスコアを達成しました。これに対し、同じ論文でAI(o1)は26.6%のスコアにとどまりました。
興味深いのは、AIエージェントは最初の数時間では人間よりも高いスコアを示したことです。しかし、時間が経つにつれて人間の方が優位に立つようになりました。AIは素早くコードを書く能力に優れていますが、長時間かけて問題を解決し改善していく能力では人間に劣るようです。
人間の研究者は最初の数時間ではスコアが低いままでした(論文を理解するのに時間がかかるため)が、24時間以降に大幅な進展を見せました。
タスクタイプ別の性能分析
タスクタイプ別に分析すると、AIは以下のような特徴を示しました:
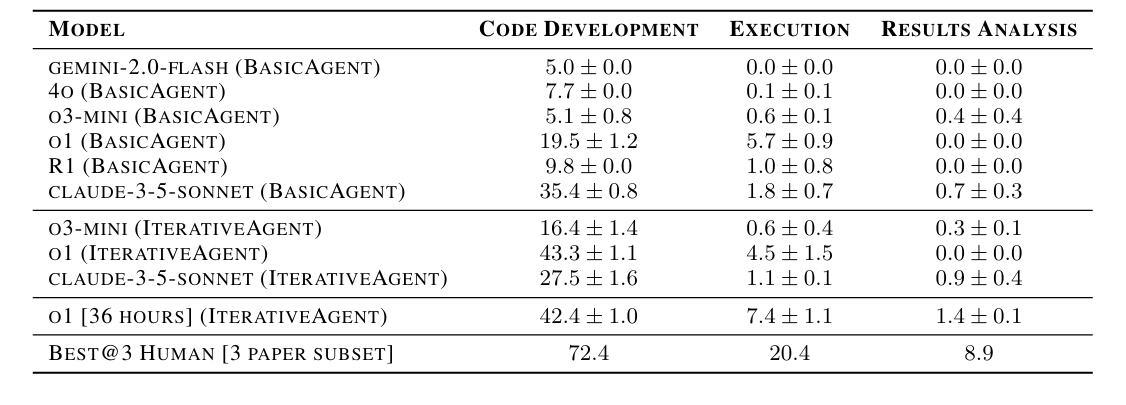
- ・コード開発: 比較的高いスコア(Claude 3.5 Sonnetで35.4%)
- ・実行: 大幅に低下(Claude 3.5 Sonnetで1.8%)
- ・結果一致: 最も低い(Claude 3.5 Sonnetで0.7%)
この結果は、AIがコードを書くことは得意でも、そのコードを実際に動かして結果を出すことはまだ苦手であることを示しています。特に複数のコンポーネントを統合したり、エラーをデバッグしたりする能力が不足していると考えられます。
より手軽な評価方法「PaperBench Code-Dev」
PaperBenchの完全な評価は計算リソースとAPIコストの両面で高価です。例えば、OpenAI o1を使用して12時間の評価を実行する場合、1つの論文あたり約400ドル(約6万円)のAPIコストがかかります。20本の論文すべてでは、これは8,000ドル(約120万円)以上に相当します。
このコスト問題に対処するため、研究チームは「PaperBench Code-Dev」という簡略化されたバージョンも提供しています。これはコードの実行部分を省略し、コード開発部分のみを評価することでコストを大幅に削減します。GPUハードウェアの要件も不要となり、採点コストも約85%削減されます。
このPaperBench Code-DevでのOpenAI o1のスコアは43.4%に達し、コード開発に焦点を当てた場合のAIの能力の高さが示されています。
PaperBenchの限界と課題
研究チームはPaperBenchにいくつかの限界があることも正直に述べています:
- 1.データセットの規模
現在は20本の論文のみが対象であり、AI研究の多様性を完全に反映しているわけではありません
- 2.データ汚染の可能性
論文の著者が公開しているコードをAIが学習時に見ている可能性があります(これを「コンタミネーション(データ汚染)」と呼びます)
- 3.評価基準作成の労力
詳細な採点基準の作成には専門家の多大な時間が必要です
- 4.自動採点の限界 -
AIによる自動採点は完璧ではなく、誤判定の可能性があります
- 5.コスト
評価の実行コストが高く、広範な実験を行うのが難しい場合があります
まとめ・研究の意義と今後の展望
PaperBenchは、AIが研究論文を自律的に再現する能力を測定する重要な一歩を提供しています。現在のAIエージェントは人間の研究者のレベルには達していないものの、特定の領域では着実な能力を示しています。
この研究の主な貢献は:
- 1.AI研究論文の再現能力を客観的に評価する手法の提供
- 2.将来のAIシステムの能力向上を測定するためのベースラインの確立
- 3.AIの長期的なタスク実行能力における現在の限界の特定
OpenAIはPaperBenchのコードをオープンソースとして公開し、AI研究コミュニティ全体がこのツールを活用して、AIシステムの能力を評価・監視・予測できるようにしています。
AIが自ら研究を進める能力は科学的発見を加速させる可能性があると同時に、リスク評価やガバナンスが追いつかないままAI技術が急速に進化するリスクも示唆しています。PaperBenchのようなベンチマークはこうした能力の進化を測定し、社会が準備するための重要な役割を果たすことになるではないでしょうか。













.png&w=3840&q=75)